Analysing SQL Server Agent Job History
The SQL Server Agent has always been a key part of the setup at wherever I've worked. It's easy to use and cheaper than a third party tool. It's an out of the box way of scheduling ETL processes, an essential feature for running a data warehouse operation.
A typical agent job might run an SSIS package or stored procedure, or call a PowerShell script. The job monitor would always be open on our screens and we'd check it every so often, looking out for failed jobs or just to see what was currently running, e.g. if that report data for finance had finished loading. So the SQL Server Agent was central to our day to day operation, but we had no way of analysing its history to answer interesting questions like: which jobs / steps were taking the longest to run, which ones had failed recently, is a currently running job taking longer than normal to complete?
In this post I'll go through a method of capturing SQL Server Agent job history, storing it in a data mart that we create, and using it for analysis. First we'll examine the limitations of using the history maintained by SQL Server. Then we'll look at an alternative solution and demonstrate a use for it: sending alerts for long running jobs.
Problems with the built in job history
SQL Server persists job history in msdb.dbo.sysjobhistory and there are settings to control how it does so. They're on the history page of the properties dialog for the agent:
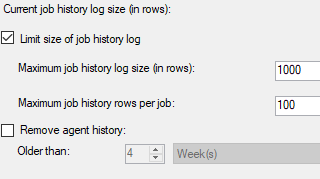
These are the default settings. Unfortunately, in real life, you need more than 1,000 rows and 100 rows per job. Where I've worked the SQL Server Agent usually had dozens of jobs, each running on a different cadence, e.g., daily, weekly, monthly backup and ETL jobs, or jobs that run on demand at random times. The problem is that the more frequently running jobs tend to flush out the history of the less frequently running jobs leading to an unfair amount of history for the frequent jobs (e.g. hourly incremental jobs), and very little history for the less frequent jobs (e.g. weekly bulk loads). It gets worse because every step in a job is logged, so steps (e.g. configuration steps) that take less than a second, and have no value for analysis, effectively just bloat the history table.
To fix this I just set both numbers really high, e.g. to 999,999. But this leads into the next problem: the "Remove agent history" checkbox doesn't do what you think it does . While it does remove history, it only does it once; it doesn't set up a recurring deletion. If you check the box and close the dialog then open it again, you'll discover that, while it did remove the specified amount of history, the box is back to being unchecked. So clearing history means repeating this every time, which isn't practical. Read another explanation of these problems here.
Behind the scenes SQL Server clears the history by calling the stored procedure msdb.dbo.sp_purge_jobhistory, meaning you can get around the quirkiness of the checkbox by calling this stored procedure, e.g., in a job that runs daily:
--put this in a job and run it daily to clear the last 30 days
DECLARE @Cleanup datetime;
SET @Cleanup = DATEADD(day, -31, CURRENT_TIMESTAMP);
EXECUTE msdb.dbo.sp_purge_jobhistory @oldest_date = @Cleanup;
We'll bake this into the solution.
The Solution
I got the basic idea from Ed Pollack but I've put my own stamp on it. We create a star schema data model and load with it data from the views in msdb that contain SQL Server Agent information, i.e. these:
msdb.dbo.sysjobhistorymsdb.dbo.sysjobs
We can collect as much history as we want and it will serve analytical queries much better than the history table dbo.sysjonhistory, which, by the way, is a pain to use because it stores dates and times as integers. There is a system function called msdb.dbo.agent_datetime for handling these integer dates and times, which is used in the solution. It takes a date and a time (as integers) and returns them, combined, into a DATETIME:
SELECT msdb.dbo.agent_datetime(20240501, 103000)
--result
--2024-05-01 10:30:00.000 (a DATETIME)
The data model
A star schema consists of a fact table surrounded by dimensions that it joins to. It's not as normalized as an OLTP schema but it's better suited to analytical queries that read and aggregate large amounts of data. A fact table row generally represents a real life event, a fact, like a sale. It's also referred to as the grain of the table. Fact columns are a mixture of foreign keys to dimensions, and the numerical amounts that are values of the facts that the business wants to measure, like sales amount or sold quantity. Dimensions decorate the facts with useful information, like customer type, sales territory, etc.
A dimensional model for SQL Server Agent job history has two granularities of interest: job and job step, although, for brevity, I'm only showing the job level data mart in this post. The grain of the job fact table (called FactAgentJobRunTime) is a single instance of a job that has run and is identified by the instance_id column of dbo.sysjobhistory. We'll set it as the clustered primary key and rename it FactAgentJobRunTimeId:
CREATE TABLE dbo.FactAgentJobRunTime
(
FactAgentJobRunTimeId INT NOT NULL
CONSTRAINT PK_FactJobHistory PRIMARY KEY CLUSTERED,
DimDateId INT NOT NULL,
[Time] TIME NOT NULL,
DimAgentJobId INT NOT NULL,
[Status] NVARCHAR(20) NOT NULL,
DurationSeconds INT NOT NULL,
Inserted DATETIME2 NOT NULL
CONSTRAINT DFT_FactJobHistory_Inserted
DEFAULT (SYSDATETIME()),
Updated DATETIME2 NOT NULL
CONSTRAINT DFT_FactJobHistory_Updated
DEFAULT (SYSDATETIME())
)
This fact table joins to the standard warehouse date dimension and the agent job dimension below:
CREATE TABLE dbo.DimAgentJob
(
DimAgentJobId INT IDENTITY(1, 1) NOT NULL
CONSTRAINT PK_DimAgentJob
PRIMARY KEY CLUSTERED(DimAgentJobId),
JobId UNIQUEIDENTIFIER NOT NULL,
JobName NVARCHAR(200) NOT NULL,
[Description] NVARCHAR(MAX) NULL,
Inserted DATETIME2 NOT NULL
CONSTRAINT DFT_DimAgentJob_Inserted
DEFAULT (SYSDATETIME()),
Updated DATETIME2 NOT NULL
CONSTRAINT DFT_DimAgentJob_Updated
DEFAULT (SYSDATETIME())
)
GO
CREATE UNIQUE INDEX UQ_DimAgentJob_AgentJobId
ON dbo.DimAgentJob(JobId)
GO
We load this dimension with data from the msdb.dbo.sysjobs table. We only need three columns for this dimension: job_id, name, and description. job_id uniquely identifies the job but I don't use it as the clustering key because GUIDs make bad clustering keys (or do they?). So I use a surrogate key, an ever-increasing integer.
The stored procedure below uses MERGE to load the dimension. I've adopted the convention of prefixing stored procedure names with a verb, e.g. dbo.LoadTable:
CREATE OR ALTER PROCEDURE dbo.LoadDimAgentJob
AS
MERGE INTO dbo.DimAgentJob AS tgt
USING
(
SELECT
job_id AS JobId,
[name] AS JobName,
[Description]
FROM
msdb.dbo.sysjobs
) AS src
ON tgt.jobId = src.JobId
WHEN NOT MATCHED THEN INSERT
(
JobId,
JobName,
[Description],
Inserted,
Updated
)
VALUES
(
JobId,
JobName,
[Description],
DEFAULT,
DEFAULT
)
WHEN MATCHED AND
(
tgt.[Description] <> src.[Description]
OR tgt.JobName <> src.JobName
)
THEN UPDATE SET
tgt.[Description] = src.[Description],
tgt.JobName = src.JobName,
tgt.Updated = SYSDATETIME();
Any changes are overwritten making it a Type-1 slowly changing dimension.
Here's the date dimension, which I create with the help of this tip from Aaron Bertrand. I like the date dimension key to be "smart", i.e. an integer of the form YYYYMMDD.
-- prevent set or regional settings from interfering with
-- interpretation of dates / literals
SET DATEFIRST 1, -- 1 = Monday, 7 = Sunday
DATEFORMAT dmy,
LANGUAGE US_ENGLISH; --couldn't find a UK English
-- assume the above is here in all subsequent code blocks.
DECLARE @StartDate date = '20200101';
DECLARE @CutoffDate date = DATEADD(DAY, -1, DATEADD(YEAR, 30, @StartDate));
;WITH seq(n) AS
(
SELECT 0 UNION ALL SELECT n + 1 FROM seq
WHERE n < DATEDIFF(DAY, @StartDate, @CutoffDate)
),
d(d) AS
(
SELECT DATEADD(DAY, n, @StartDate) FROM seq
),
src AS
(
SELECT
[DimDateId] = CONVERT(INT,
CONVERT(NVARCHAR(4), DATEPART(YEAR, d))
+ RIGHT('00' + CONVERT(NVARCHAR(2), DATEPART(MONTH, d)),2)
+ RIGHT('00' + CONVERT(NVARCHAR(2), DATEPART(DAY, d)),2)
),
TheDate = CONVERT(date, d),
TheDay = DATEPART(DAY, d),
TheDayName = DATENAME(WEEKDAY, d),
TheWeek = DATEPART(WEEK, d),
TheISOWeek = DATEPART(ISO_WEEK, d),
TheDayOfWeek = DATEPART(WEEKDAY, d),
TheMonth = DATEPART(MONTH, d),
TheMonthName = DATENAME(MONTH, d),
TheQuarter = DATEPART(Quarter, d),
TheYear = DATEPART(YEAR, d),
TheFirstOfMonth = DATEFROMPARTS(YEAR(d), MONTH(d), 1),
TheLastOfYear = DATEFROMPARTS(YEAR(d), 12, 31),
TheDayOfYear = DATEPART(DAYOFYEAR, d)
FROM d
)
SELECT *
INTO dbo.DimDate
FROM src
ORDER BY TheDate
OPTION (MAXRECURSION 0);
ALTER TABLE dbo.DimDate ALTER COLUMN DimDateId INT NOT NULL
ALTER TABLE dbo.DimDate ADD CONSTRAINT PK_DimDate PRIMARY KEY CLUSTERED(DimDateId)
I haven't bothered with a time dimension. Whenever I'm dealing with time it's usually hourly aggregates, which are simple enough to get with DATEPART(HOUR, [Time]).
This stored procedure loads the fact table:
CREATE OR ALTER PROCEDURE dbo.LoadFactAgentJobRunTime
AS
;WITH StageFactAgentJobRunTime AS
(
SELECT
FactAgentJobRunTimeId = jh.instance_id
,DimDateId = jh.run_date
,[Time] = CONVERT(TIME(0), msdb.dbo.agent_datetime(jh.run_date, jh.run_time), 114)
,DimAgentJobId = aj.DimAgentJobId
,[Status] = CASE jh.run_status
WHEN 0 THEN N'Failed'
WHEN 1 THEN N'Succeeded'
WHEN 2 THEN N'Retry'
WHEN 3 THEN N'Canceled'
WHEN 4 THEN N'In Progress'
ELSE N'Unknown'
END
,RunDurationSeconds = DATEDIFF(SECOND, 0, CAST(msdb.dbo.agent_datetime(jh.run_date, jh.run_duration) AS TIME))
FROM
msdb.dbo.sysjobs AS j
INNER JOIN msdb.dbo.sysjobhistory AS jh
ON jh.job_id = j.job_id
INNER JOIN dbo.DimAgentJob AS aj
ON j.job_id = aj.JobId
WHERE
/*Ignoring the steps*/
jh.step_id = 0
/*Rare, but had a negative duration once*/
AND jh.run_duration > 0
)
INSERT INTO dbo.FactAgentJobRunTime
(
FactAgentJobRunTimeId
,DimDateId
,[Time]
,DimAgentJobId
,[Status]
,DurationSeconds
,Inserted
,Updated
)
SELECT
s.FactAgentJobRunTimeId
,s.DimDateId
,s.[Time]
,s.DimAgentJobId
,s.[Status]
,s.RunDurationSeconds
,SYSDATETIME() AS Inserted
,SYSDATETIME() AS Updated
FROM
StageFactAgentJobRunTime AS s
WHERE
NOT EXISTS
(
SELECT *
FROM dbo.FactAgentJobRunTime AS f
WHERE f.FactAgentJobRunTimeId = s.FactAgentJobRunTimeId
)
/*Purge history*/
DECLARE @Cleanup datetime;
SET @Cleanup = DATEADD(day, -31, CURRENT_TIMESTAMP);
EXECUTE msdb.dbo.sp_purge_jobhistory @oldest_date = @Cleanup;
GO
Note the step at the end that purges history older than 31 days. Change this to suit your needs.
That's basically it. We have a simple dimensional model to analyse agent job history. Load it by calling the stored procedures in order (dimensions first, as always):
EXEC dbo.LoadDimAgentJob
GO
EXEC dbo.LoadFactAgentJobRunTime
GO
It's recommended to run this as a T-SQL batch in a job that runs daily.
Now we can use the data mart to see if a currently running job is taking longer than usual.
How to see if a job's duration is unusual
To identify long running jobs we need a baseline from which to compare a currently running job. The data model we've created, assuming it has a reasonable amount of history (you might have to collect data for a few weeks), is perfect for this. But first here's a few handy views. One encapsulates the warehouse query to make it feel like querying one table:
CREATE OR ALTER VIEW dbo.vwFactAgentJobRunTime
AS
SELECT
j.JobId,
f.FactAgentJobRunTimeId,
j.JobName,
dt.[TheDate],
f.[Time],
f.[Status],
f.DurationSeconds
FROM
dbo.FactAgentJobRunTime AS f
INNER JOIN dbo.DimDate AS dt
ON f.DimDateId = dt.DimDateId
INNER JOIN dbo.DimAgentJob AS j
ON f.DimAgentJobId = j.DimAgentJobId
GO
This second view calculates summary statistics:
CREATE OR ALTER VIEW dbo.vwJobSummaryStatistics
AS
SELECT
JobId
,JobName
,COUNT(*) AS Runs
,AVG(DurationSeconds) AS AvgDurationSeconds
,MIN(DurationSeconds) AS MinDurationSeconds
,MAX(DurationSeconds) AS MaxDurationSeconds
,CAST(STDEVP(DurationSeconds) AS DECIMAL(10,1)) AS StdDevDurationSeconds
FROM
dbo.vwFactAgentJobRunTime
WHERE
[Status] = N'Succeeded'
GROUP BY
JobId,
JobName
GO
I learned in Thomas LaRock's tip how statistics can be used to find long running jobs. The test is: if the job's current runtime is greater than the average runtime + 2 standard deviations, then we consider it an outlier worth investigating. How do you get currently running jobs? Andy M. Mallon has got a TVF for this that can be cross applied to sysjobs to find jobs running now:
CREATE OR ALTER FUNCTION dbo.AgentJobStatus (@JobName sysname)
RETURNS TABLE
AS
RETURN
SELECT TOP 1
JobName = j.name,
JobId = j.job_id,
IsRunning = CASE
WHEN ja.job_id IS NOT NULL
AND ja.stop_execution_date IS NULL
THEN 1 ELSE 0
END,
RequestSource = ja.run_requested_source,
LastRunTime = ja.start_execution_date,
NextRunTime = ja.next_scheduled_run_date,
LastJobStep = js.step_name,
RetryAttempt = jh.retries_attempted,
JobLastOutcome = CASE
WHEN ja.job_id IS NOT NULL
AND ja.stop_execution_date IS NULL THEN 'Running'
WHEN jh.run_status = 0 THEN 'Failed'
WHEN jh.run_status = 1 THEN 'Succeeded'
WHEN jh.run_status = 2 THEN 'Retry'
WHEN jh.run_status = 3 THEN 'Cancelled'
END
FROM msdb.dbo.sysjobs j
LEFT JOIN msdb.dbo.sysjobactivity ja
ON ja.job_id = j.job_id
AND ja.run_requested_date IS NOT NULL
AND ja.start_execution_date IS NOT NULL
LEFT JOIN msdb.dbo.sysjobsteps js
ON js.job_id = ja.job_id
AND js.step_id = ja.last_executed_step_id
LEFT JOIN msdb.dbo.sysjobhistory jh
ON jh.job_id = j.job_id
AND jh.instance_id = ja.job_history_id
WHERE j.name = @JobName
ORDER BY ja.start_execution_date DESC;
GO
Below is the final query, putting all the pieces together. The table-valued function, dbo.AgentJobStatus, is cross applied to dbo.sysjobs to filter on jobs that are running now. The summary statistics view is also joined in order to perform the test (in the WHERE clause), i.e., is the current runtime > average runtime + 2 standard deviations. If a result is returned then we have a long running job that needs further investigation. You could wrap this in an IF EXISTS block that sends an alert, using database mail, to the team's inbox.
;WITH cte AS
(
SELECT
v.JobId
,v.JobName
,v.Runs
,v.AvgDurationSeconds
,v.StdDevDurationSeconds
,sts.LastRunTime
,DATEDIFF(SECOND,sts.LastRunTime,GETDATE()) AS CurrentRunTime
,v.AvgDurationSeconds + 2 * v.StdDevDurationSeconds AS AvgPlus2StDev
FROM msdb.dbo.sysjobs j
CROSS APPLY dbo.AgentJobStatus (j.name) AS sts
INNER JOIN dbo.vwJobSummaryStatistics AS v
ON j.job_id = v.JobId
WHERE
sts.IsRunning = 1
)
SELECT
*
FROM cte
WHERE CurrentRunTime > AvgPlus2StDev
This is the kind of thing a monitoring tool would be constantly on the lookout for. Perhaps you could put this in a job that runs every minute or so.
Limitations
This is a good starting point, but there are some problems. Outliers, for example, because real world data is riddled with them. I've got a good six months' worth of data and the outliers can throw off the standard deviation. It could be remedied by excluding the highest two or three data points because they do tend to be massive outliers.
Another problem is with the test we used: that a value lying further than two standard deviations from the mean is an outlier. I'm not sure how well this hold up if you've got really skewed data, and most real world data is skewed, or at least my real world data is very skewed! Of course there are other statistical techniques you could use but those are beyond the scope of this article (i.e. I've mostly forgotten what I learned in those statistics modules).
Summary
This post looked at the SQL Server Agent, a useful feature for scheduling jobs like like backups and ETL pipelines. The runtime history has some great insights, but can easily be neglected, perhaps because the data in the msdb job tables isn't easy to use, or worse, there's a distinct lack of history because you didn't change the default settings. But you can create your own data model, which we did, and showed one use for it: to alert the team about jobs that appear to be stuck running in a loop.