How Outdated Statistics Impact Performance
Statistics inform the optimizer's cost-based decision about which execution plan to use so it's important to keep them up to date. Out of date statistics might lead the optimizer to choose a suboptimal plan, one that doesn't accurately reflect the underlying distribution of data in the table. For example it could mean that an index seek and lookup is selected when a clustered index scan would have been better.
Luckily SQL Server does most of the work in maintaining statistics: it creates them automatically and updates them after a certain number modifications. These settings are on by default and it's best to keep them on.
--on by default
ALTER DATABASE AdventureWorks2017 SET AUTO_CREATE_STATISTICS ON;
ALTER DATABASE AdventureWorks2017 SET AUTO_UPDATE_STATISTICS ON;
But there are times when statistics need to be manually created or updated. Perhaps the threshold for updating them hasn't been reached, or AUTO_UPDATE_STATISTICS is turned off, or they haven't been created because AUTO_CREATE_STATISTICS is turned off. Or you might need statistics for multi-column predicates where there isn't an index. In these cases the missing missing or out of date statistics are responsible for a decrease in performance because the optimizer's didn't chose a suitable plan.
Fixing it
The cure is basically to adopt the preventative policy of not letting statistics get stale in the first place. A popular solution is the one provided free by Ola Hallengren. It creates an agent job that basically runs index and statistics maintenance on a schedule that suits you.
Example
Here's an example. First the set up to create a table dbo.Test1 with a uniform distribution of data:
USE AdventureWorks2017
GO
SET NOCOUNT ON;
SET STATISTICS IO, TIME ON;
--turning these off for the demo
ALTER DATABASE AdventureWorks2017
SET AUTO_CREATE_STATISTICS OFF;
ALTER DATABASE AdventureWorks2017
SET AUTO_UPDATE_STATISTICS OFF;
/*Setup*/
DROP TABLE IF EXISTS dbo.Test1
GO
CREATE TABLE dbo.Test1
(
c1 INT IDENTITY(1, 1),
c2 INT
)
GO
INSERT INTO dbo.Test1(c2)
SELECT TOP (100000)
ROW_NUMBER() OVER(ORDER BY
(SELECT NULL))
FROM
master.dbo.spt_values AS a,
master.dbo.spt_values AS b
GO
CREATE INDEX IX_Test1 ON dbo.Test1(c2)
GO
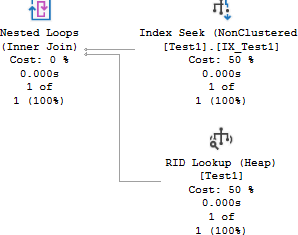
Next run this simple SELECT query and look at the execution plan. It's a seek and lookup which is good for this query because it's a selective predicate that returns 1 row. Performance is 3 logical reads, 23ms.
/*Seek + lookup -- GOOD
3 logical reads, 23ms*/
SELECT * FROM dbo.Test1 WHERE c2 = 1
Now lets simulate some modifications that alter the distribution dramatically. And then run the above query again:
/*Do modifications that alter distribution*/
UPDATE dbo.Test1 SET c2 = 1 WHERE c1 < 100000
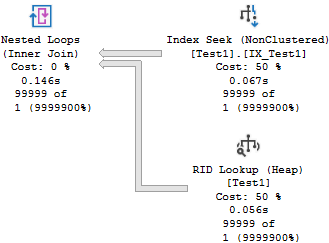
/*Seek + lookup -- this time BAD
100381 logical reads, 395ms*/
SELECT * FROM dbo.Test1 WHERE c2 = 1
It's the same plan and notice how SQL Server estimated 1 row for the index seek operator but the actual row count turned out to be 99,999. Well the stale statistics are to blame. Performance got worse: 100,381 logical reads, 395ms.
Updating the statistics manually (but in the real world it would have updated by default):
UPDATE STATISTICS dbo.Test1
/*Table scan -- GOOD
211 logical reads*/
SELECT * FROM dbo.Test1 WHERE c2 = 1
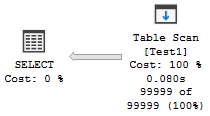
The plan is now more appropriate: a table scan. Performance has improved in terms of logical reads (211), but in time not so much (385ms).